
El 18/05/23 un cliente trae un equipo que presentaba problemas varios, uno de mis mantras es revisar, PRIMERO QUE NADA, la salud de disco y lo primero que se observa son errores pendientes de traslación de sectores (current pending sectors), en cristiano es: el disco tiene sectores que están incongruentes y por lo tanto el firmware dentro del disco va a trasladarlos a sectores seguros pero no puede completar la tarea y queda registrado.
No le pierdo un segundo mas y le aviso al cliente que hay que cambiar el disco, pide un truco de magia para seguir con ese equipo ya que es el que gestiona, en una de sus repetidoras de FM, la programación diaria y que las licencias de los programas (antiquísimos) están "atachados" a ese disco, se le avisa que esto puede durar muy poco tiempo pero igual insiste (si me piden..., yo también hago "macanas" a pedido), limpio el sistema y tomo captura, remarco en rojo la cantidad de hs. del disco que explica en parte porque sucede lo que le sucede. Los fabricantes de discos se apoyan en una métrica de "resistencia" con siglas MTBF (tiempo medio entre fallas) que las cifran en promedio en 1.5 millones de hs.. El disco mas longevo que conozco es un IBM en un servidor de HP con 80.000 hs y andando, la evidencia de años enseña que a partir de las 20.000 es común ver "problemitas", en 30 años solo ví un disco que tenía mas de 40.000 hs de trabajo y el susodicho Ultrastar de IBM.

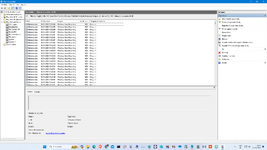
el 07/11/23 el cliente vuelve con el equipo pero ya es imposible trabajar, verifico y aparece lo siguiente:

Como se aprecia, se incrementaron los sectores pendientes pero ahora se le sumaron errores de CRC (Control de Redundancia Cíclica), estos últimos son muy comunes y no tienen mayor impacto siempre y cuando no estén acompañados de otros representativos y que además no sean masivos..... el hecho que hayan aumentado los valores S.M.A.R.T. (C5), Current Pending Sector, es claro indicativo de falla degenerativa, se han observado discos con estos "detalles" pero estaban estables, cosa que no es la norma, pero meses después si siguen en los mismos valores, todos felices.
Y acá viene la parte "Forensic", puesto a analizar lo que le sucedió en ese tiempo que es una ventana de 857hs se notan algunas "sutilezas" analizando esa gran bitácora que es el visor de eventos.
Se observa que el sistema está "verborrágico" pero el dato que alerta es la distribución temporal de dicha "verborragia", son ráfagas en pocos segundos, si bien el nivel, columna nivel, es informativa, no está en amarillo de advertencia ni en rojo de error, se podría creer que no es relevante y realmente el mensaje no es de relevancia para el sistema pero con esa cadencia puede dejar exhausto al equipo debido a que en esa captura solo estamos viendo un evento ordenado pero siguen habiendo otros eventos contemporáneos a esos

Veamos algunos mas, pero en este caso miren que curioso, quien se está quejando.... el desfragmentador....

Todas las "flechitas" van en la misma dirección.........
Una última muestra de "verborragia" y no molesto más, después siguen las graves....

Es notable ver que de 9710 eventos registrados en esa ventana temporal del análisis, 6062 corresponden exclusivamente al evento 1001 que corresponde a BEX (Buffer overflow EXception) este evento en particular inundó al visor de eventos y si nos fijamos en la distribución temporal tiene una baja cadencia, curiosamente el sistema no lo tiene en amarillo advirtiendo, para el es normalito y es muy común de la familia Win10 sin mayores problemas funcionales...... recordar que hay MUY muchos otros eventos produciéndose, en otras palabras, le están pegando flor de paliza al sistema que debe "distraer" recursos registrándolos y lidiando con ellos de alguna manera.
Hasta ahora solo vimos una partecita super pequeñísima que expone "detallitos" y que está medio esquizoide...... el log ya analizado fué Application, es donde se anotan las novedades, digamos, mas "soft", ahora veamos a System que es la parte "hard" y mas representativa.
Esto es un verdadero festín de fallas "hard", hay para todos los gustos.

En orden numérico de ID:
26- marcado inocentemente como de nivel info, pero es un error de escritura demorada..!!!! en cristiano: tenía datos en un buffer de escritura a disco, el disco hace unos instantes estaba presente pero ahora que me decido a grabar los datos, desapareció!!! y como ya despaché los datos se perdierooooon...!!!!, si el equipo estuviera en una red, es sintomático de que la red está herrrrrrrmosa de lo bien que pierde "visión" de los recursos compartidos y si no está en red, bueno...perdió de vista al disco en una operación, justo, pero justo, justito..... de vaciado de caché de lecto/escritura.
50-es la confirmación del mensaje anterior pero con mas datos de ubicación, lo curioso aquí es que debería estar encima y no por debajo pero como las diferencias son en milésimas de segundos de separación, a veces alguno se cuela antes....
51-error de paginación de dispositivo \DR1, ni idea de que es pero viendo los dos anteriores creo que son primitos.
55-daño estructural del sistema de archivos.....literal
129-se emitió un restablecimiento de dispositivo, \Device\RaidPort0......... já, te reinicio el disco y listo, a ver el guapo que proteste, a ver prrrrrrrrr............
140-el sistema no pudo vaciar datos en el registro de transacción. Es posible que se produzcan daños en VolumenId: esto es muy malo, malosamente malo, malísimo!!!!! es muy largo de explicar y algo sofisticado, pero créanme, es malísimo......
153-se reintentó la operación de E/S en la dirección de bloque lógico 0x5f3398 del disco 1=daño de superficie en HD y si fuera un SSD, daño en celda
Notar que en el espacio de 18 minutos se sucedieron los errores graves, curiosamente antes de esa hora habían errores mucho menos serios y pocos.
Resumiendo:
El disco registró un tiempo de uso de 857 hs. pero la cuenta de 170 días entre fechas dan mas de 4000 hs, cliente mendaz.
El mismo día, antes de traer el equipo, instaló un programa llamado DriverDoc, es evidente que pensó que era un problema de drivers.
No se puede/debe encarar la reparación de un equipo informático sin antes recolectar información veraz y suficiente, se pueden responder preguntas muy generales con respuestas muy generales, podemos aventurar, podemos apostar, yo creo, tal vez, puede ser.
EL visor de eventos tiene la historia de lo bueno y de lo malo y es el antídoto contra la brujería técnica.
No le pierdo un segundo mas y le aviso al cliente que hay que cambiar el disco, pide un truco de magia para seguir con ese equipo ya que es el que gestiona, en una de sus repetidoras de FM, la programación diaria y que las licencias de los programas (antiquísimos) están "atachados" a ese disco, se le avisa que esto puede durar muy poco tiempo pero igual insiste (si me piden..., yo también hago "macanas" a pedido), limpio el sistema y tomo captura, remarco en rojo la cantidad de hs. del disco que explica en parte porque sucede lo que le sucede. Los fabricantes de discos se apoyan en una métrica de "resistencia" con siglas MTBF (tiempo medio entre fallas) que las cifran en promedio en 1.5 millones de hs.. El disco mas longevo que conozco es un IBM en un servidor de HP con 80.000 hs y andando, la evidencia de años enseña que a partir de las 20.000 es común ver "problemitas", en 30 años solo ví un disco que tenía mas de 40.000 hs de trabajo y el susodicho Ultrastar de IBM.
el 07/11/23 el cliente vuelve con el equipo pero ya es imposible trabajar, verifico y aparece lo siguiente:
Como se aprecia, se incrementaron los sectores pendientes pero ahora se le sumaron errores de CRC (Control de Redundancia Cíclica), estos últimos son muy comunes y no tienen mayor impacto siempre y cuando no estén acompañados de otros representativos y que además no sean masivos..... el hecho que hayan aumentado los valores S.M.A.R.T. (C5), Current Pending Sector, es claro indicativo de falla degenerativa, se han observado discos con estos "detalles" pero estaban estables, cosa que no es la norma, pero meses después si siguen en los mismos valores, todos felices.
Y acá viene la parte "Forensic", puesto a analizar lo que le sucedió en ese tiempo que es una ventana de 857hs se notan algunas "sutilezas" analizando esa gran bitácora que es el visor de eventos.
Se observa que el sistema está "verborrágico" pero el dato que alerta es la distribución temporal de dicha "verborragia", son ráfagas en pocos segundos, si bien el nivel, columna nivel, es informativa, no está en amarillo de advertencia ni en rojo de error, se podría creer que no es relevante y realmente el mensaje no es de relevancia para el sistema pero con esa cadencia puede dejar exhausto al equipo debido a que en esa captura solo estamos viendo un evento ordenado pero siguen habiendo otros eventos contemporáneos a esos
Veamos algunos mas, pero en este caso miren que curioso, quien se está quejando.... el desfragmentador....
Todas las "flechitas" van en la misma dirección.........
Una última muestra de "verborragia" y no molesto más, después siguen las graves....
Es notable ver que de 9710 eventos registrados en esa ventana temporal del análisis, 6062 corresponden exclusivamente al evento 1001 que corresponde a BEX (Buffer overflow EXception) este evento en particular inundó al visor de eventos y si nos fijamos en la distribución temporal tiene una baja cadencia, curiosamente el sistema no lo tiene en amarillo advirtiendo, para el es normalito y es muy común de la familia Win10 sin mayores problemas funcionales...... recordar que hay MUY muchos otros eventos produciéndose, en otras palabras, le están pegando flor de paliza al sistema que debe "distraer" recursos registrándolos y lidiando con ellos de alguna manera.
Hasta ahora solo vimos una partecita super pequeñísima que expone "detallitos" y que está medio esquizoide...... el log ya analizado fué Application, es donde se anotan las novedades, digamos, mas "soft", ahora veamos a System que es la parte "hard" y mas representativa.
Esto es un verdadero festín de fallas "hard", hay para todos los gustos.
En orden numérico de ID:
26- marcado inocentemente como de nivel info, pero es un error de escritura demorada..!!!! en cristiano: tenía datos en un buffer de escritura a disco, el disco hace unos instantes estaba presente pero ahora que me decido a grabar los datos, desapareció!!! y como ya despaché los datos se perdierooooon...!!!!, si el equipo estuviera en una red, es sintomático de que la red está herrrrrrrmosa de lo bien que pierde "visión" de los recursos compartidos y si no está en red, bueno...perdió de vista al disco en una operación, justo, pero justo, justito..... de vaciado de caché de lecto/escritura.
50-es la confirmación del mensaje anterior pero con mas datos de ubicación, lo curioso aquí es que debería estar encima y no por debajo pero como las diferencias son en milésimas de segundos de separación, a veces alguno se cuela antes....
51-error de paginación de dispositivo \DR1, ni idea de que es pero viendo los dos anteriores creo que son primitos.
55-daño estructural del sistema de archivos.....literal
129-se emitió un restablecimiento de dispositivo, \Device\RaidPort0......... já, te reinicio el disco y listo, a ver el guapo que proteste, a ver prrrrrrrrr............
140-el sistema no pudo vaciar datos en el registro de transacción. Es posible que se produzcan daños en VolumenId: esto es muy malo, malosamente malo, malísimo!!!!! es muy largo de explicar y algo sofisticado, pero créanme, es malísimo......
153-se reintentó la operación de E/S en la dirección de bloque lógico 0x5f3398 del disco 1=daño de superficie en HD y si fuera un SSD, daño en celda
Notar que en el espacio de 18 minutos se sucedieron los errores graves, curiosamente antes de esa hora habían errores mucho menos serios y pocos.
Resumiendo:
El disco registró un tiempo de uso de 857 hs. pero la cuenta de 170 días entre fechas dan mas de 4000 hs, cliente mendaz.
El mismo día, antes de traer el equipo, instaló un programa llamado DriverDoc, es evidente que pensó que era un problema de drivers.
No se puede/debe encarar la reparación de un equipo informático sin antes recolectar información veraz y suficiente, se pueden responder preguntas muy generales con respuestas muy generales, podemos aventurar, podemos apostar, yo creo, tal vez, puede ser.
EL visor de eventos tiene la historia de lo bueno y de lo malo y es el antídoto contra la brujería técnica.
Adjuntos
Última edición:



